
요약
회의 상황에서 이종 디바이스(노트북, 스마트폰)로 녹음한 여러 데이터를 다채널 음성 데이터로 간주
시스템
multi-channel audio stream alignment -> blind beamforming
-> speech recognition -> speaker diarization (with speaker profile)
-> system combination(CNC, ROVER)
제안된 모델의 성능은 overlap speech가 없는 경우
IHM(헤드셋) 음성 데이터를 사용했을 때 대비 WER 3% 차이
실험 데이터
회의 참가자의 30초 분량 voice profile 준비
30분~1시간 평소 회의 5개 분량, 3~11명의 참가자
3개의 회의는 이종 디바이스 7개로 녹음 (이중 4개는 IOS, 3개는 안드로이드)
2개의 회의는 7채널 마이크 배열로 녹음
overlap speech는 전체 발화의 약 10%
시스템 구성
상대적으로 빠른 음성인식 결과를 실시간으로 뽑고, diarization 결과는 나중에 보여줌
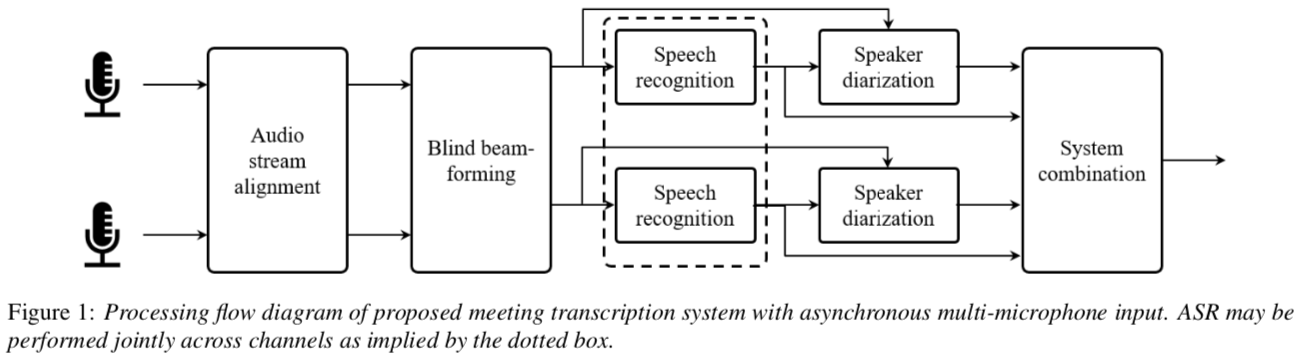
Audio stream alignment
채널 하나를 reference로 정하고(어떻게?), 나머지 채널을 reference에 맞춤.
global time lag 추정
1초 단위로 cross-correlation 을 계속 계산하여 두드러진 peak를 global time lag으로 정한다.
offline 레코딩의 경우 기기 간 time lag 차이가 몇분일 수 있기 때문에 non-reference 신호에 대해 windowing을 해가며 time lag을 찾는다.
global time lag을 보정한 후...
두 가지 버퍼를 사용
sample 단위의 time lag을 계산하기 위한 버퍼 (30초 길이)
reference 신호에 대해 cross-correlation 계산, delay 값만큼 output buffer의 샘플을 버리거나 추가. (딜레이를 보정한다는 말인듯?)
output buffer
2초 후 output buffer에 밀어넣은 만큼 빼내어 다음 모듈에 전달한다.
Blind beamforming
LSTM으로 N, Y 마스크 추정 후 MVDR 빔포밍
M개의 채널에 대해 M-1개의 채널을 선택하여 빔포밍을 M번 수행, M개의 enhanced output
speaker recognition
M개의 enhanced 채널에 대해 M번 수행
0.3초 이상 silence 단위로 문장을 구분하여 음성인식 수행
speaker diarization
회의 참가자들의 보이스 프로필 30초 분량을 미리 확보하고, 화자별 dvector를 준비해둠.
resnet으로 dvector 추출 → agglomerative clustering(??) 으로 clustering → 미리 준비해둔 dvector와 유사도를 계산하여 화자 id 부여
system combination
이 부분이 제일 중요한데 잘 이해 안됨.
M개의 신호에 대해 음성인식이 수행되므로 ROVER, CNC를 사용하여 하나의 결과로 만듬.
ROVER: voting 기반의 음성인식 결과 combination
CNC: confusion network combination.
여러 모델에서 나오는 posterior를 기반으로 다시 디코딩 하는 것이라는데... 잘 모르겠음. 그냥 1-best 결과로 lattice 다시 만들고 다시 디코딩하는 건지?
실험 결과
SAWER: 화자 별 WER
online, offline이 뒤섞여 있음... 공평한 비교라고 할 수 없음. 어느 수준에서 online이고 offline인지도 잘 모르겠음.
CNC + beamforming 조합이 제일 좋고, CNC의 기여가 큼.
맨 아래 IHM은 헤드셋 마이크로 녹음한 데이터

언뜻 beamforming이 성능 향상에 기여하는 것 같으나, 위 실험 결과와 같이 생각해보면 사실은 CNC의 기여가 대부분.

(overlap 발화를 제외하면) 제안된 시스템의 성능이 헤드셋 마이크를 통해 음성인식한 결과와 3% 밖에 차이가 안남.

결론: overlap 발화에 대한 처리가 챌린지
댓글 없음:
댓글 쓰기